이번 포스트에서는 저번 포스트에서 Json에 대해 알아보았으니
이번에는 AST 추상 구문 트리와 nearly.js를 이용한 Json Parser를 만들어보는 것을 다뤄보도록 하겠습니다.
https://ww8007-learn.tistory.com/13
[1] Json에 대해서 알아보기 - 기초
웹 개발을 하다 보면 Json을 수도 없이 마주치게 되는데요 요번 글에서는 Json에 대해서 좀 더 깊이 알아보고 이를 파싱할 수 있는 Parser까지 만들어보는 포스트를 1, 2 편에 나눠서 다뤄보려고 합니
ww8007-learn.tistory.com
parser를 만들기 위한 첫 번째 관문 : AST - 추상 구문 트리
AST가 뭘까요?
위키백과에 따르면 다음과 같습니다.
컴퓨터 과학에서 추상 구문 트리 (abstract syntax tree, AST), 또는 간단히 구문 트리
(syntax tree)는 프로그래밍 언어로 작성된 소스 코드의 추상 구문 구조의 트리이다. 이 트리의 각 노드는 소스 코드에서 발생되는 구조를 나타낸다. 구문이 추상적이라는 의미는 실제 구문에서 나타나는 모든 세세한 정보를 나타내지는 않는다는 것을 의미한다. 예를 들어, 그룹핑을 위한 괄호는 암시적으로 트리 구조를 가지며, 분리된 노드로 표현되지는 않는다. 마찬가지로, if-condition-then 표현식과 같은 구문 구조는 3개의 가지에 1개의 노드가 달린 구조로 표기된다.
https://ko.wikipedia.org/wiki/%EC%B6%94%EC%83%81_%EA%B5%AC%EB%AC%B8_%ED%8A%B8%EB%A6%AC
추상 구문 트리 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 유클리드 호제법을 사용하여 다음의 코드를 나타낸 추상 구문 트리: while b ≠ 0 if a > b a := a − b else b := b − a return a 컴퓨터 과학에서 추상 구문 트리(abstract sy
ko.wikipedia.org
간단하게 설명하자면 추상 구문 트리(AST)는 구문 분석 트리의 단순화된 압축 버전이라고 보시면 됩니다.
컴파일러의 설계의 맥락에서는 AST는 다음과 같은 의미로 사용되고 있습니다.
AST
구문 분석 트리에 포함되는 상당한 양의 구문 정보를 무시함
원본 텍스트 분석과 관련된 정보만 포함하고 텍스트를 구문 분석하는 동안 사용되는 다른 추가 컨텐츠는 건너뜀
결국 저희가 바라보고 싶은 정보만 바라볼 수 있게 도와주는 게 AST입니다.
대학교의 전공 서적을 정리해 나만의 정리 노트를 만든다고 생각하면 좀 더 이해가 쉽겠죠? 😃
그렇다면 구문 분석 트리는 무엇일까요?
- 표현식, 문장 또는 텍스트가 어떻게 생겼는지 정확하게 나타냄
- 텍스트의 구체적인 구문을 나타내므로 구체적인 구문 트리 또는 CST라고도 부름
쉽게 생각해서 대학교 때 모든 정보를 담고 있는 전공 서적이라고 이해하시면 됩니다.
근데 이렇게만 봐서는 조금 이해가 힘들 수도 있으니 실제 예시를 통해서 알아보도록 하겠습니다.
AST를 좀 더 파헤쳐 보자
만약 다음과 같은 식이 있다고 가정해 볼게요
5 + (2 * 3)사람은 이를 2와 3을 먼저 곱하고 1을 더해야 한다는 사실을 알고 있지만 컴퓨터는 이를 어떻게 해석하게 될까요?
1. Scanner를 이용한 텍스트 스캔 -> lexemes(어휘소) 변환
컴퓨터는 위 식을 컴파일을 통해서 해석을 하게 되는데
컴파일 과정에서 가장 먼저 일어나는 일이 스캐너를 이용해 텍스트 스캔을 하게 됩니다.
텍스트 스캔을 하게 된 결과는 어휘소(lexemes)라는 작은 부분으로 나뉘게 되죠.
이는 언어에 구애받지 않는다는 특징을 가지고 있습니다.
2. lexer / tockenizer를 이용한 토큰으로 변환 작업
위에서 만들어진 lexer가 렉서 / 토크나이저로 전달되어 식을 사용하는 언어에 해당하는 고유한 토큰으로 변환하게 됩니다.
토큰은 다음과 같아요.
[5, +, (, 2, x, 3, )]3. parser 트리 빌드
이제 만들어진 토큰들을 파서로 전달하고 이를 종합해서 parser 트리를 빌드하게 됩니다.
트리로 표현하면 다음과 같이 표현될 수 있어요.
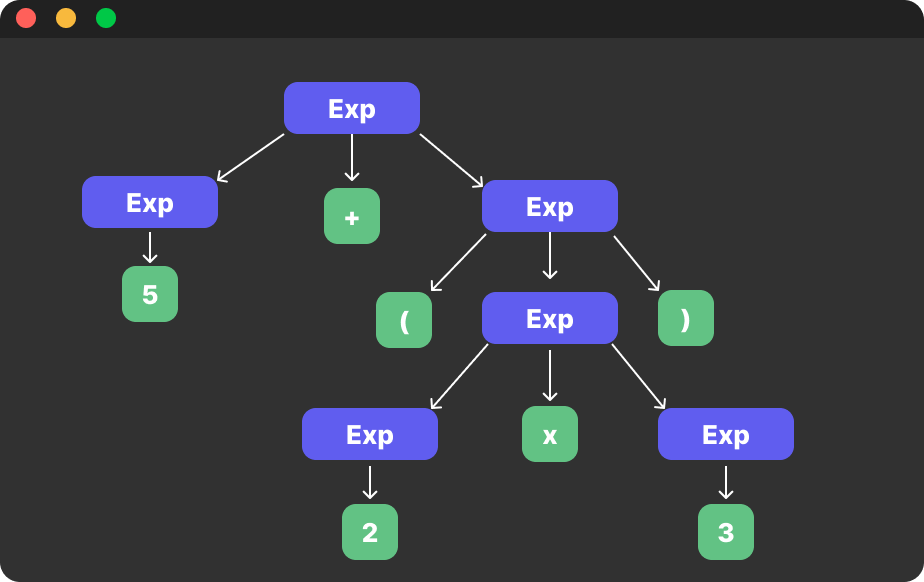
4. 구문 분석 트리 압축하기
근데 과연 여기 있는 정보들이 모두 필요한 정보 정보일까요? 🤔
11이라는 결과를 얻기 위해서는 괄호와 (), Exp에 관한 정보들은 없어도 이해하는데 아무런 문제가 없겠죠
그렇기에 저희는 이들을 제거할 수 있습니다.
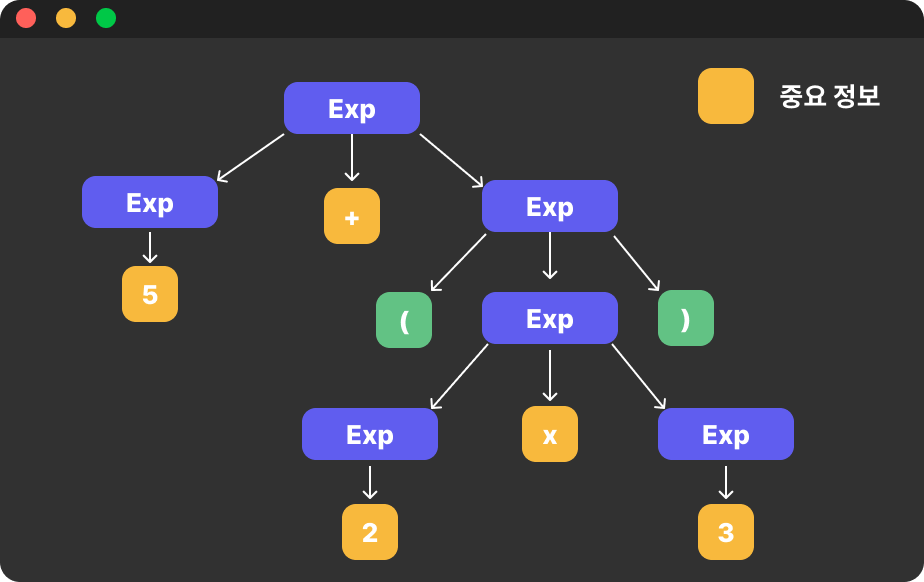
이 과정을 구문 분석 트리를 압축한다고 하는데 현재 Exp라는 부모 노드는
트리를 구문 분석한 후에는 아무런 추가 정보를 제공하지 않기 때문에 우리는 이들을 제거해 나가도 문제가 없는 거죠
또한 () 괄호의 경우 트리를 배치하는 데는 도움을 주지만
우리는 곱하기 연산자에 전달될 피연산자들을 이미 알고 있기 때문에 이들을 제거해 나갈 수 있습니다.
최종 AST 트리의 모습

이로써 저희에게 필요 없는 정보들은 모두 제거했습니다.
그럼 처음 저희가 가지고 있던 구문 분석 트리와는 어떤 점들이 달라졌을까요?
- AST는 쉼표, 괄호 및 세미콜론(언어에 따라 다름)과 같은 구문 세부 정보를 포함하지 않아요
- AST는 단일 후속 노드로 나타내지는 값들의 축소된 버전을 가지게 됩니다. 위의 트리를 보면 정확하게 알 수 있죠
- 연산자 토큰(Ex : +, -, x, /)은 구문 분석 트리에서 종료되는 리프가 아닌 트리의 상위 노드가 됩니다.
이로써 저희는 구문 분석 트리의 압축된 버전인 AST를 가지게 되었습니다.
AST 트리는 구문 분석 트리에서 내가 제거하고 싶은 정보가 있다!
하면 언제든 만들어서 자신이 보고 싶은 정보만 볼 수 있게 만들어 줍니다.
일종의 추상화라고 바라보아도 괜찮겠죠?
parser를 만들기 위한 두 번째 관문 : nearly.js
그럼 이제 본 주제인 Json 파서를 만들어보기 전에 AST 트리를 만들 수 있는 도구를 정해야 하는데요
JS에는 파서를 만들 수 있는 여러 라이브러리를 제공합니다.
- nearley.js
- PEG.js
- Choevrotain
- jison
이 중에서 요번에는 가장 학습이 쉬운 nearly.js를 이용해서 json 파서를 구현해보려고 합니다.
유연한 문법을 제공하는 대신 성능이 좀 떨어진다고는 하는데 추후에 다른 파서 라이브러리들로 동일하게 구현을 해보면서
성능 비교를 해봐도 좋을 것 같네요 😃
또한 플레이그라운드를 제공해 줘서 웹에서 바로바로 테스트를 진행해 보실 수 있습니다.
https://omrelli.ug/nearley-playground/
Nearley Parser Playground | Parse Grammars Online, From The Comfort Of Your Home!
omrelli.ug
그럼 공식 문서를 따라 몇 가지 문법들을 배워볼까요?
표현식 작성 하기
다음과 같은 방법으로 표현식을 작성해 줄 수 있습니다.
변수 같은 개념으로도 사용할 수 있어요
expression -> number "+" number
expression -> number "-" number
expression -> number "*" number
expression -> number "/" number
number -> [0-9]:+
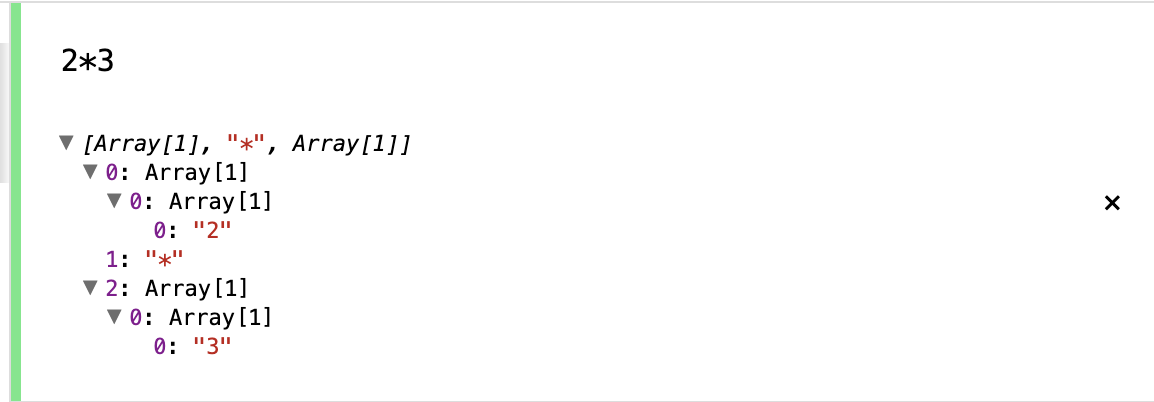
else 문 같이 사용하기
| 를 사용해서 다음과 같이 또는 문을 작성이 가능합니다.
expression ->
number "+" number
| number "-" number
| number "*" number
| number "/" number
postproseccor
nearly의 경우 규칙과 일치하는 모든 항목을 배열로 래핑 합니다.
그렇기에 저희가 원하는 결괏값을 뽑아내기 위해서 후 처리기를 제공하죠.
방식은 다음과 같습니다.
expression -> number "+" number {%
function(data) {
return {
operator: "sum",
leftOperand: data[0],
rightOperand: data[2] // data[1] is "+"
};
}
%}
number -> [0-9]:+ {% d => parseInt(d[0].join("")) %}

이제 직접 json parser 만들기
이제 문법도 어느 정도 알았으니 이를 이용해서 저번 시간에 다루었던 Json의 특징을 nearly로 이용해서 작성해 보겠습니다.
Json 문자열에서 이스케이스 시퀀스 처리와 숫자에 대한 정수, 소수점 처리만 조금? 신경 써 주면 됩니다.
# JSON 요소부터 시작
Json -> Element
# JSON Element 정의, JSON에서 유효한 모든 값이 될 수 있음
Element -> Value
# JSON Value 정의
Value -> Object
| Array
| String
| Number
| "true"i
| "false"i
| "null"i
# JSON Object 정의
Object -> "{" _ "}" {% () => ({}) %}
| "{" _ Members _ "}" {% (d) => d[2] %}
# Object 내의 Members 정의
Members -> Member {% (d) => d[0] %}
| Member _ "," _ Members {% (d) => Object.assign({}, d[0], d[4]) %}
# Object 내의 Member 정의
Member -> String _ ":" _ Element {% (d) => ({ [d[0]]: d[4] }) %}
# JSON Array 정의
Array -> "[" _ "]" {% () => ([]) %}
| "[" _ Elements _ "]" {% (d) => d[2] %}
# Array 내의 Elements 정의
Elements -> Element {% (d) => [d[0]] %}
| Element _ "," _ Elements {% (d) => [d[0]].concat(d[4]) %}
# JSON String 정의
String -> "\"" Characters "\"" {% (d) => d[1] %}
# String 내의 Characters 정의
Characters -> null {% () => "" %}
| Character Characters {% (d) => d[0] + d[1] %}
# String 내의 Character 정의
Character -> [^"\\] {% id %}
| EscapedChar {% id %}
# Escape 처리된 문자 정의
EscapedChar -> "\\" ["/" "\\" "b" "f" "n" "r" "t" "\""] {% (d) => JSON.parse("\"" + "\\" + d[1] + "\"") %}
| "\\u" [0-9a-fA-F] [0-9a-fA-F] [0-9a-fA-F] [0-9a-fA-F] {% (d) => JSON.parse("\"" + "\\" + "u" + d[1] + d[2] + d[3] + d[4] + "\"") %}
# JSON Number 정의
Number -> "-":? [0-9]:+ "." [0-9]:+ {% (d) => Number((d[0] ? d[0].join('') : "") + '.' + d[2].join('')) %}
| "-":? [0-9]:+ {% (d) => Number((d[0] ? d[0].join('') : "") + d[1].join('')) %}
# 공백 (무시됨) 정의
_ -> [ \t\n\r]:* {% () => null %}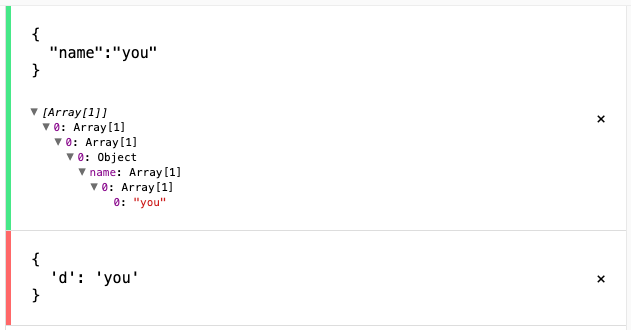
결과를 보게 되면 저희가 의도한 대로 key, value가 잘 나오게 되는 것을 알 수 있습니다.
만약 두 번째 테스트 같이 비표준 Json 구문을 정상적으로 파싱 하고 싶다면 어떻게 해야 할까요?
# JSON String 정의
String -> "\"" Characters "\"" {% (d) => d[1] %}
| "'" Characters "'" {% (d) => d[1] %}위와 같이 홀 따옴표 구문도 OR 절도 처리해서 파싱을 진행할 수 있습니다.
이제 마음껏 Json을 가지고 놀 수 있겠네요 😎

마무리
이렇게 해서 AST 추상 구문 트리와, nearly에 대한 문법, nearly를 이용한 Json Parser까지의 구현을 모두 마쳤습니다.
쉽다고 소개되었던 nearly 문법이 조금 난해해서 이해하는데 어려움이 있었지만
구문 트리를 AST 트리로 만들면서 제가 원하는 정보만 추출할 수 있게 된 것 같아 조금은 기쁘네요 😁
추후에 다른 js 파서 라이브러리들을 이용해서 json 파서를 구현해 보고 성능 비교와
babel parser나 TS parser를 다뤄보도록 하겠습니다.
참고 문서
Home - nearley.js - JS Parsing Toolkit
Home Parsers turn strings of characters into meaningful data structures (like a JSON object!). nearley is a fast, feature-rich, and modern parser toolkit for JavaScript. nearley is an npm Staff Pick. nearley 101 Install: $ npm install -g nearley (or try ne
nearley.js.org
https://medium.com/basecs/leveling-up-ones-parsing-game-with-asts-d7a6fc2400ff
Leveling Up One’s Parsing Game With ASTs
Before I started on this journey of trying to learn computer science, there were certain terms and phrases that made me want to run the…
medium.com
'JavaScript' 카테고리의 다른 글
| 내가 사용하는 yarn 최선일까? (0) | 2023.11.12 |
|---|---|
| Intersection Observer에 대해서 알아보자 (1) | 2023.03.24 |
